 Pythonによるデータ分析
Pythonによるデータ分析
Pythonによるデータ分析
Pythonによるデータ分析
多変量解析 や グラフィカル分析 をする時ですが、 例えば、平日の分析をしたいのに休日のデータが混ざっている場合や、 関係をみたいデータが別々の表にまとまっている場合は、思っているような分析ができないです。 こういう時は、データの切り貼りが必要です。
データが少しなら、コピーペーストでできますが、 多くなって来るとやりきれなくなります。 このページは、多い時の話です。
リレーショナルデータベース の中にあるデータを使う場合は、データをデータベースから取り出す時に、SQLを使って、切り貼りも一緒にすることができます。 巨大なデータをそのまま抽出しようとすると、処理し切れなくなるので、その意味でもこの作業は大事です。
筆者が社会人になったばかりの頃のExcelは、約6万行しか入らなかったですし、パソコンもよくフリーズしました。 2020年現在のExcelとパソコンなら、ビジネス現場のたいていのデータは、問題なく扱えます。 ひとつの表になっているデータを切り貼りするのなら、 ピボットテーブル でたいていの加工はできます。
※ このページは、データが目の前にある状態がスタートになっています。 目の前にあるデータに、頭の中の情報を追加する方法は、 メタ知識のデータの作成 になります。
以下の、コードは、「df」や「df1」、「df2」という形でフレーム形式のデータが入力されている状態がスタートになっています。 データがcsvファイルの場合は、入力方法は下記になります。
import pandas as pd # パッケージの読み込み
df= pd.read_csv("Data.csv" , engine='python')# データを読み込む
日本語が含まれていないなら、「engine='python'」はなくても良いです。
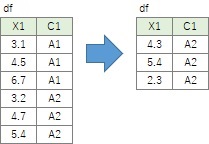
層別
は、冒頭の例のように、注目したいデータだけを取り出す方法です。
df[df.C1 == 'A1']
X1が3と4の間になっている行を取り出す場合は、下記になります。
df[(df.X1 > 3) & (df.X1 <4)]
AND条件は「&」、OR条件は「|」、NOT条件は「~」を使います。
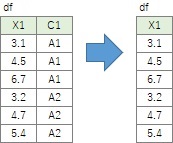
次元削減の方法としては、
主成分分析
を使って、量的変数を集約する方法がありますが、
ここでは単純に変数を絞る方法です。
df.X1
または、
df.loc[:,['X1']]
2つの表を単純に貼り合わせる方法は、縦に並べる場合と、横に並べる場合があります。
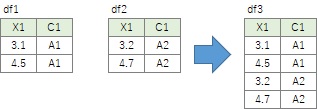
df3 = pd.concat([df1, df2]) # 縦に貼り合わせる。
縦に貼り合わせた時に、お互いに持っていない変数の値は、欠損値(NaN)になります。
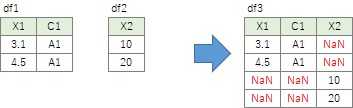
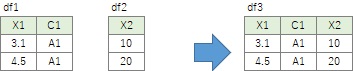
df3 = pd.concat([df1, df2],axis=1)# 横に貼り合わせる。
横に貼り合わせる時は、各行は完全に対応していることが前提になっています。
例えば、下の例のようなことが起こります。
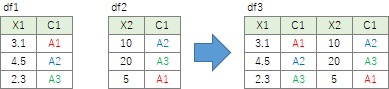
データの内容によるのですが、A1、A2、A3の行が一致していて欲しい時は、 2つの表のデータの並び方が異なる場合は、どちらかに合わせてから使う必要があります。
並び替えをしない方法としては、 下記のmergeを使った方法もあります。 mergeの場合は、例えば、片方の表にA2がなくて、並び替えても行が一致しない場合でも合体できます。
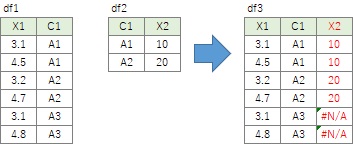
これは、左(left)のdf1に、右のdf2を紐付ける場合になります。 Excelなら、VLOOKUP関数を使う処理です。 df2に「A3」がないので、「#N/A」という文字列が入っています。
Pythonで上記と同じ処理を行う場合は、下記のコードになります。
「#N/A」のところは、「NaN」と書かれて来ます。
df3=pd.merge(df1,df2, how='left')
「left」の所は、一致のない行は抽出しない場合、「inner」です。 右の表から見た時に、左の表にない行も含める場合は、「outer」です。
